

End-to-End Speech Recognition with Raw Audio Singals and 1D Convolutions
Convolutional neural networks are a powerful form of neural networks. Their coverage ranges from classifying images and identifying multiple objects in a video feed, to writing or responding to real-time conversations. Most of these convolutional networks are several layers deep and use data in a matrix form. This example focuses on a different kind of shallow neural network that uses one-dimensional array-shaped data to build a simple speech recognition system that classifies raw audio files into 30 different categories without requiring additional acoustic or language models. The system consists of a combination of 1D convolutions with fully connected dense layers and data augmentation in the form of noise injection. Our example shows that 1D convolutions are suitable for the feature extraction of raw audio signals and combined with fully connected layers, it can achieve a competent validation accuracy considering the low footprint and hardware requirements.
The complete code for this example can be found in my speech recognition Github repository
EDA
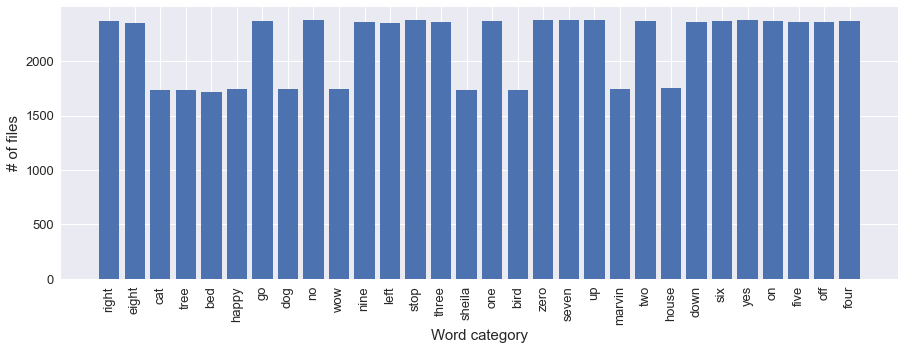
As mentioned in the title, for this exercise, we will be working with the dataset for the TensorFlow speech recognition challenge. The training set consists of 64,721 different audio files for 30 different word categories.
The number of recordings ranges from just above 1,500 for some categories to well above 2,000 for others.
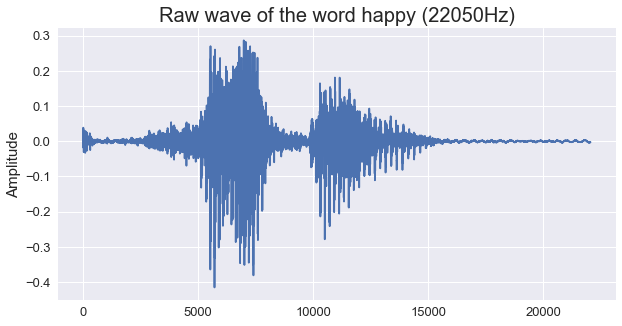
Since we are working with audio files, the sample rate and the sample values are relevant ideas to have in mind. After using the python package LibROSA to load one of the audio files, one can conclude that the original sample rate for the different audio files in the training dataset is 22,050Hz. In the next figure, shows one example of the audio signal for the word “Happy” in its original sample rate.
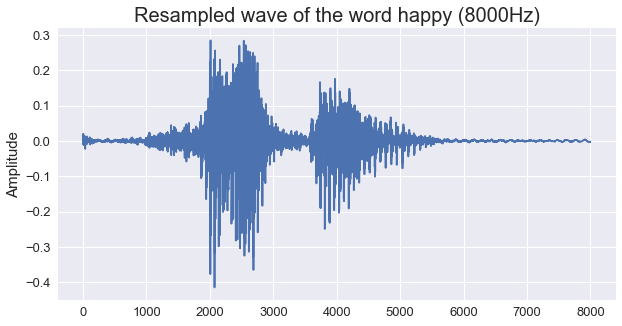
To be able to work effectively with all the files and train different models, one would like resampling the audio signals to shorters ones while keeping the fundamental features that characterize each distinct word. The figure below shows the same example of the word “Happy” after resampling.
Data Augmentation
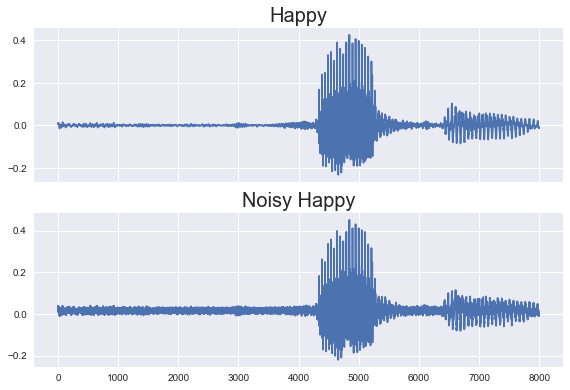
To increase the amount of data to which our model is exposed to, we have opted for the inclusion of data augmentation in the form of noise injection. The noise injection process consists of slightly modifying the samples in our audio files by adding a random number multiplied by a noise coefficient. The resulting samples, while different from the originals, still contain the essential features required for classification and most importantly, remain “audible”. In the following figure, one can observe an example of the word happy with and without background noise.
Modelling
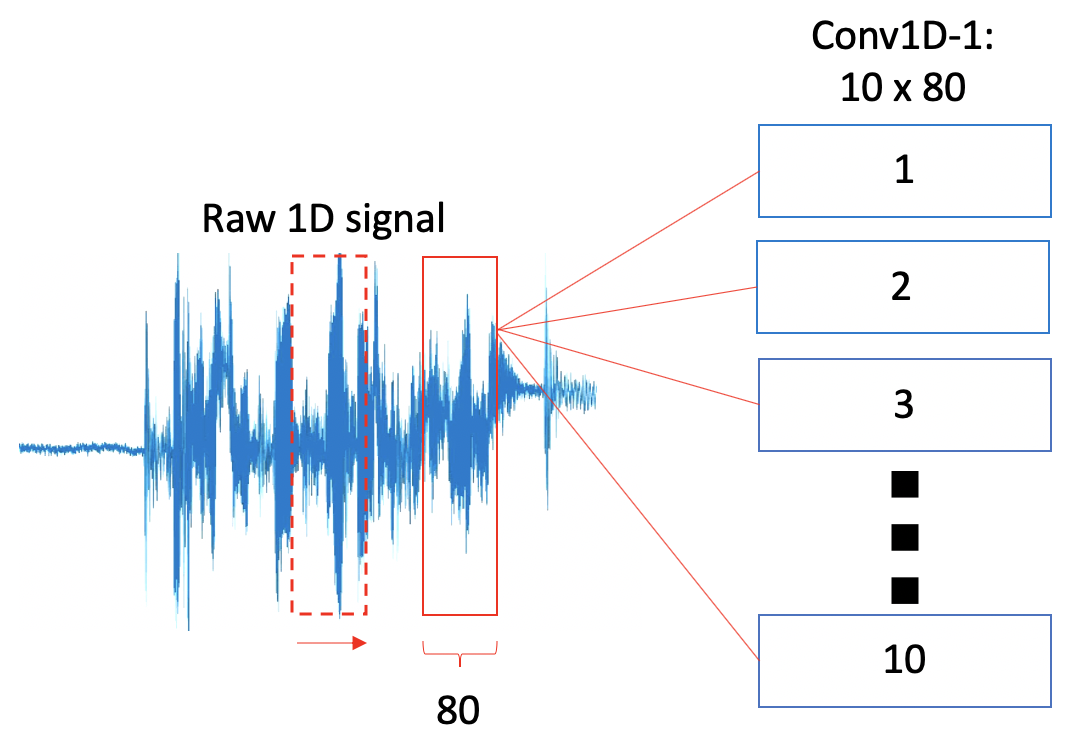
Considering that we will be working with raw audio files, we need a way to use CNNs in our problem. The answer that we have found consists of the usage of 1D Convolutions. The difference between 1D convolutions and more traditional 2D convolutions is that, unlike its pair, this layer creates a convolution kernel that is convolved with the layer input over a single spatial (or temporal) dimension to produce a tensor of outputs. In the figure below, the reader can appreciate the basic functioning of a 1D convolutional layer. In the example, the Conv1D layer has a number of filters equal to 10 and a kernel size of 80. As shown, the filter moves along the temporal axis by a quantity indicated by the “stride” hyperparameter and computes the different weights for the samples contained inside the filter space.
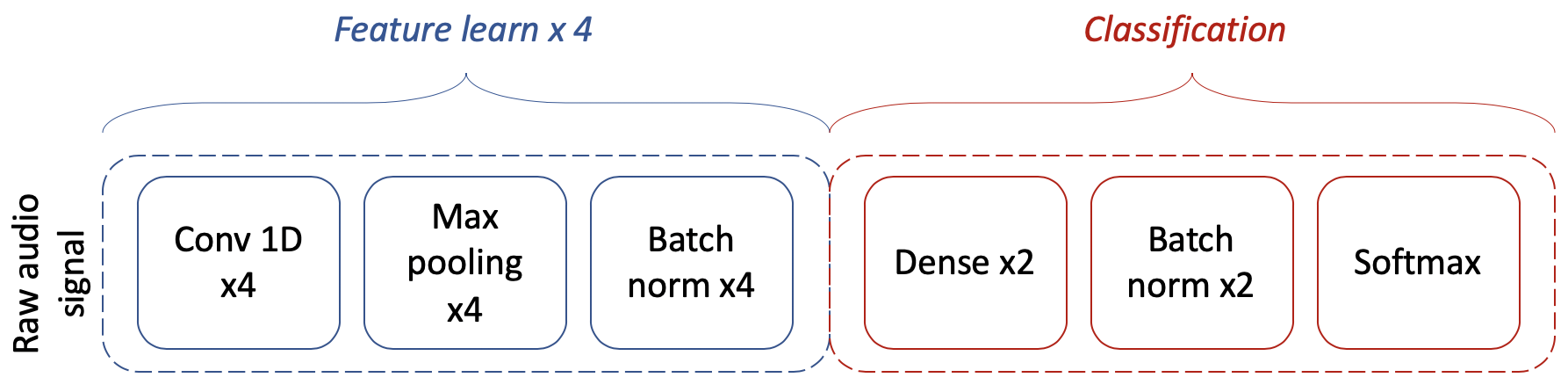
In general, we can describe our model as two-step approach in which on a first stage, the model takes the inputs and pass them through a series of convolution layers; we will refer to this as the feature extraction stage. On the second part, the model takes the outputs of the feature extraction stage and pass them through a more traditional DNN architecture that consists of three dense layers including classification layer and batch normalisations; we will refer to this as the classification stage.
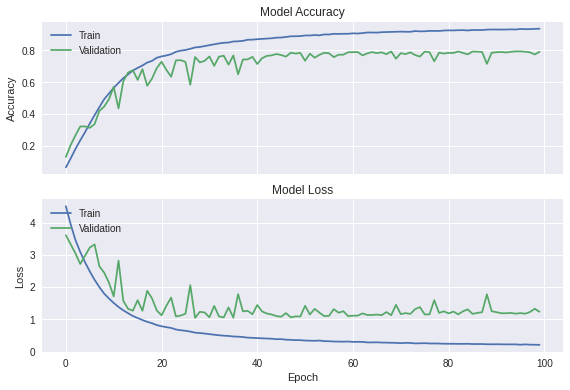
The next figure presents the results for the training process of our model using Keras. As one can observe, it yields a consistent validation accuracy close to 80%.
Conclusion
In this work, we propose a lightweight system that can be trained under two hours and produces a validation accuracy that consistently is just under 80%. The model architecture can be described as shallow and straightforward as opposed to deep and complex since we only make use of four convolution layers and three dense layers, including the last layer for classification. However, those characteristics correspond to trade-offs that we were willing to make since at the current stage we do not have the necessary resources to work with such big dataset in a way that allows faster training and therefore the necessary number of iterations that will allow further improvements.
A complete version of this example can be found in my Github repository.